We Built an Autonomous FinOps Agent. The Real Lessons Weren't About Cost.

1. Introduction: The Limits of Simple Scripts
Most of us in the cloud space have written, or at least used, simple scripts to find waste. A quick Python script to find orphaned EBS volumes is a common first step into cloud cost management. But what happens when you try to build something more? The journey from a simple scanner to a sophisticated, safety-first Multi-Agent System reveals that the most profound lessons have less to do with scripting and more to do with architecture, safety, and a new kind of infrastructure intelligence.
We set out to automate cloud cost optimization and ended up uncovering a set of powerful principles for building any kind of safe, autonomous system. These are the most impactful takeaways from that journey.
2. Takeaway 1: To Build a Safe System, Separate the Brain from the Hands
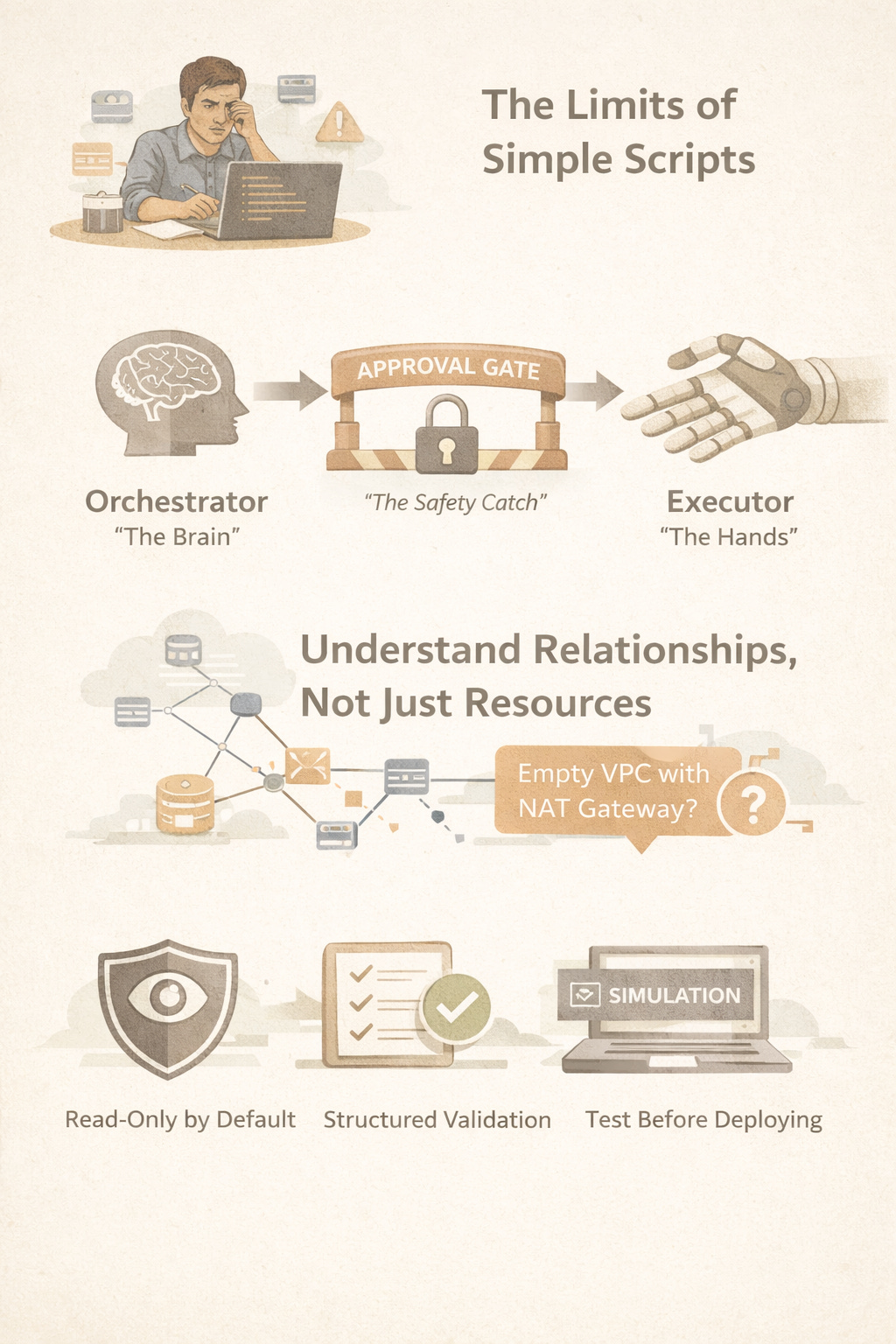
The most critical safety feature is a clean separation of concerns.
The core of our system is an architecture built on three distinct components: the Orchestrator (the Brain), the Approval Gate (the Safety Catch), and the Executor (the Hands).
The Orchestrator acts as our FinOps Architect. Its sole purpose is to establish situational awareness. It focuses exclusively on discovery and analysis, building an internal architecture graph to map dependencies and understand how resources relate to one another. It contextualizes risk, proposes a plan, and then stops.
This is where the Approval Gate comes in. It is a distinct architectural component—a mandatory “Safety Catch” that ensures no action is taken without explicit human consensus.
Only after a plan is vetted and approved does the Executor get involved. It is a focused bot that acts only on these pre-approved instructions. It’s also built for resilience; if a task fails, it can intelligently reason about the failure and ask for further permission rather than proceeding blindly.
This separation is a deliberately counter-intuitive design choice. We made the “smartest” part of the system—the one with all the context—incapable of taking direct action. This safeguard is fundamental to building trust and preventing the catastrophic accidents that can occur with powerful automation.
The Orchestrator is designed to be incapable of running destructive commands.
3. Takeaway 2: True Optimization Comes from Understanding Relationships, Not Just Resources
Focus on architectural patterns, not just isolated items.
Many cost-saving tools operate by looking for individual resources in isolation—an unattached volume, an idle instance. This approach finds obvious waste but misses larger, more complex inefficiencies.
Our system takes a “Relationship-Aware Mapping” approach. It maps the entire account to understand the why behind resource usage and how different components connect. This allows it to identify wasteful architectural patterns, not just single items. A prime example is its ability to detect an “Empty VPC with a NAT Gateway”—a classic waste scenario that simple scanners miss because no single resource appears “unused” on its own.
By understanding the intricate web of dependencies, the system can accurately calculate the “blast radius” of any potential change. This is the difference between a simple cost tool and a strategic management platform; it provides the confidence required to make changes in complex production environments.
4. Takeaway 3: Safety Isn’t a Checklist; It’s a Foundational Feature
Engineer for safety from day one.
For any system with the potential to modify production infrastructure, safety cannot be an afterthought. It must be a core feature engineered into the system’s foundation. We achieved this through a few key principles:
• Read-Only by Default: The discovery agent (the Orchestrator) is architecturally prevented from making changes. Its permissions are strictly limited to observation and analysis.
• Structured Validation: Beyond human approval, this is a technical control. It ensures the Executor only acts on vetted and properly formatted instructions from the Approval Gate, preventing it from acting on arbitrary or malformed commands.
• Simulate Everything First: All new logic, remediation scripts, and edge-case handling are rigorously tested in simulated cloud environments. This allows us to eliminate risk and validate behavior without ever touching production infrastructure.
This safety-first mindset stands in stark contrast to a “move fast and break things” culture. When dealing with complex, interconnected production systems, engineering for reliability and trust is paramount.
5. Conclusion: Beyond Cost-Cutting
Building a sophisticated autonomous system for the cloud teaches you that the real challenge isn’t writing clever scripts. It’s about developing thoughtful architecture, achieving deep contextual understanding, and embedding a safety-first mindset into every line of code. The goal shifts from building a tool that cuts costs to creating an intelligent guardian of your cloud architecture—an advisor that prevents architectural debt before it accumulates.
If we separate analysis from execution, what other complex infrastructure challenges could we safely automate?