Building an AI-Native FinOps System: From AWS Data Chaos to Cost Optimization
How we built a comprehensive data pipeline that turns scattered AWS metrics into actionable cost savings

The Problem: AWS Data is Everywhere, Insights are Nowhere
If you’ve ever tried to optimize AWS costs at scale, you know the frustration. Your billing data lives in S3 CUR files, performance metrics are scattered across CloudWatch, and cost information is buried in Cost Explorer. Each source tells part of the story, but none give you the complete picture you need to make intelligent optimization decisions.
After speaking with engineering leaders at companies spending $100K+ monthly on AWS, the same pattern emerged:
Everyone knows they’re wasting money, but no one knows exactly where or how to fix it efficiently.
Our Approach: Build the Data Foundation First
Rather than building another dashboard that shows pretty charts with incomplete data, we decided to solve the fundamental problem: data harmonization at scale.
Here’s the system we built to turn AWS data chaos into optimization gold.
Architecture Overview: Three Sources, One Truth
Our system collects data from three primary AWS sources and harmonizes them into a unified view:
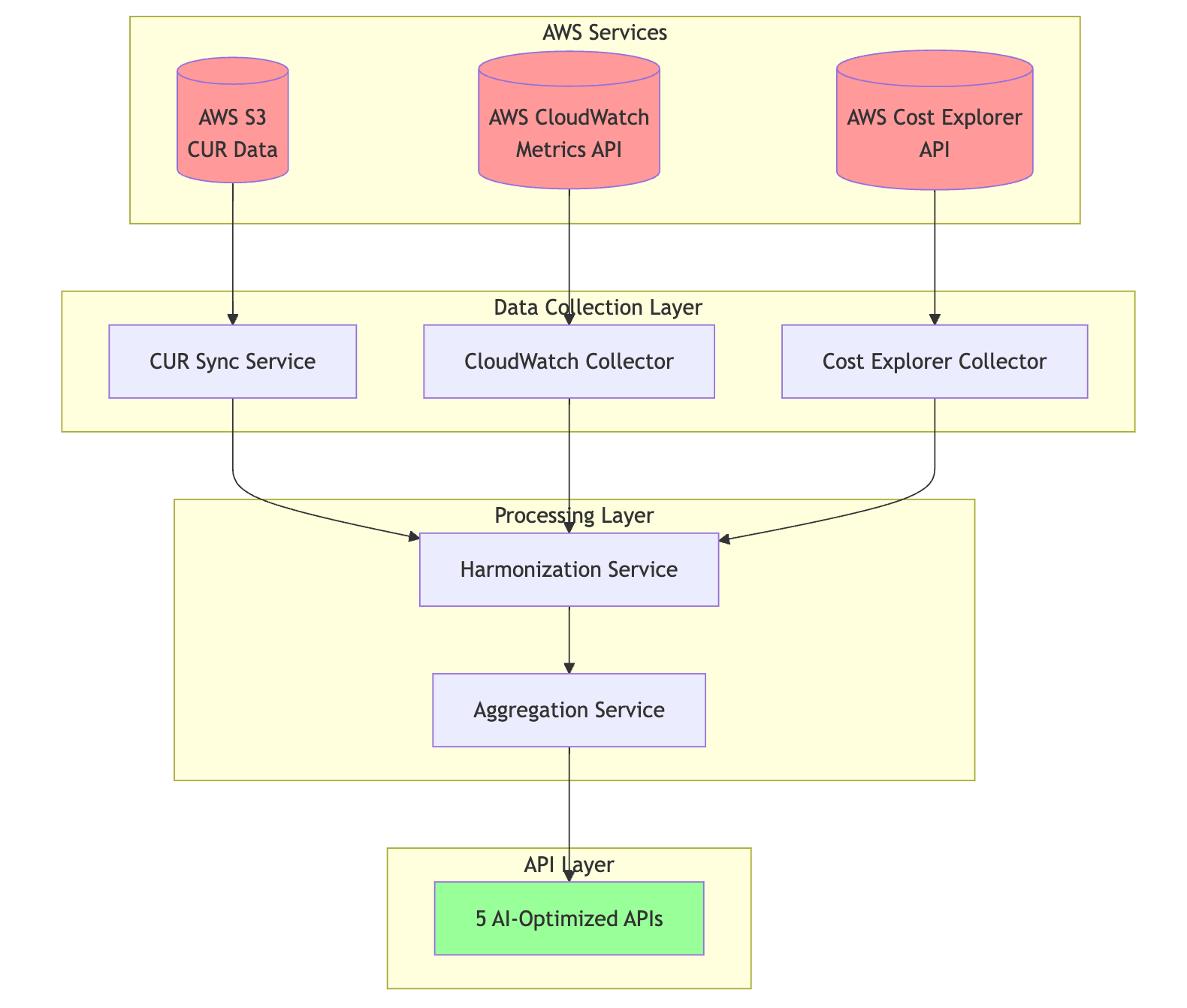
Data flows from AWS services through our collection and harmonization layers to AI-optimized APIs
1. Cost & Usage Reports (CUR): The Billing Foundation
CUR data is the most comprehensive billing source AWS provides, but it’s also the most complex to work with. We built a sophisticated sync service that:
• Smart Syncs — Checks existing data and only processes what’s needed
• Batch Processing — Handles massive CUR files (often 1GB+ compressed) efficiently
• Gap Detection — Automatically identifies and backfills missing months
• Real-time Progress — Tracks sync progress for transparency
💡 Key Insight: Current month CUR data updates throughout the day, so we sync every 6 hours. Previous months finalize within 5 days, so we sync daily during that window.
2. CloudWatch Metrics: The Performance Reality
While CUR tells you what you paid for, CloudWatch tells you what you actually used. Our collector:
• Auto-Discovery — Finds resources through CloudWatch metrics (no manual tagging required)
• Multi-Statistics — Collects Average, Maximum, and Minimum for comprehensive analysis
• Adaptive Periods — Chooses optimal time granularity (5 minutes to 1 day) based on data age
• Comprehensive Coverage — Supports EC2, RDS, Lambda, S3, DynamoDB, ELB, ECS, CloudFront, and API Gateway
💡 Key Insight: Recent data (last 24 hours) syncs hourly for real-time optimization, while historical data syncs daily for trend analysis.
3. Cost Explorer: The Real-Time Bridge
Cost Explorer provides near real-time cost data that bridges the gap between yesterday’s CUR finalization and today’s spending.
The Magic: Harmonization Engine
This is where the real innovation happens. Raw data from three sources becomes unified, AI-ready insights through our harmonization process:
Five-step harmonization process transforms scattered data into actionable insights

Step 1: Resource Collection
First, we identify every resource that appears in any data source. A single EC2 instance might appear in:
CUR data with hourly billing records
CloudWatch with CPU, memory, and network metrics
Cost Explorer with today’s running costs
Step 2: Cost Data Reconciliation
We merge unblended costs, blended costs, and real-time costs into a reconciled view that accounts for:
Reserved Instance discounts
Savings Plans applications
Spot instance pricing variations
Data variance and quality assessment
Step 3: Performance Data Processing
CloudWatch’s raw time-series data becomes actionable insights:
Statistical metrics (avg, min, max, percentiles)
Utilization trends and patterns
Performance data completeness scoring
Usage pattern detection (daily/weekly cycles)
Step 4: Efficiency Calculation
This is where cost meets performance:
Cost-per-CPU-hour calculations
Utilization efficiency scores
Right-sizing opportunity identification
Optimization potential estimation
Step 5: AI-Optimized Context Generation
Finally, we package everything into structured data that AI models can understand:
Resource utilization patterns
Cost efficiency trends
Optimization recommendations with confidence scores
Implementation guidance and risk assessment
Data Flow: From Collection to Intelligence
Here’s how data flows through our system from AWS APIs to actionable recommendations:
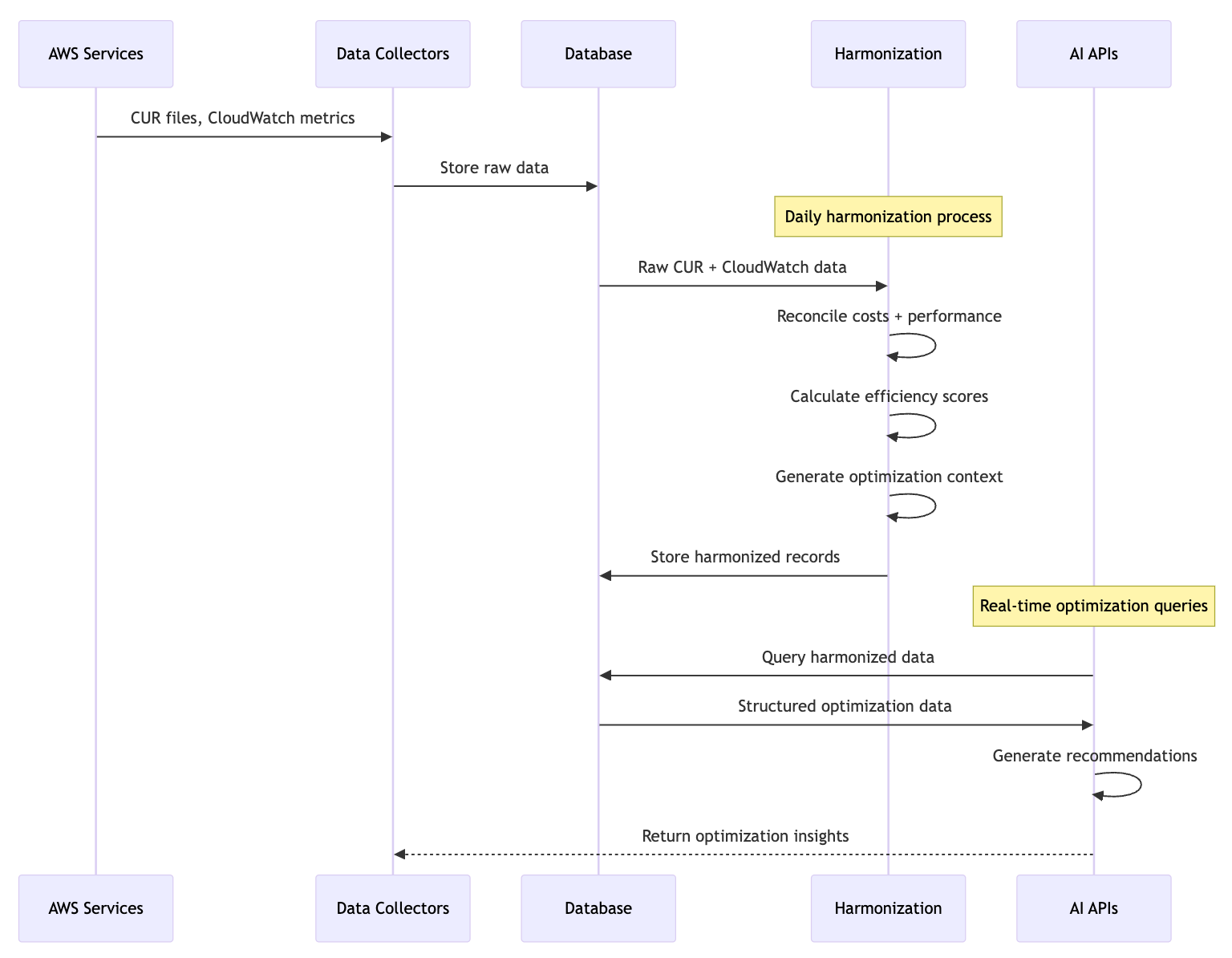
Sequential data processing from AWS services to AI-powered optimization insights
Daily Process:
AWS Services → Data Collectors (CUR files, CloudWatch metrics)
Data Collectors → Database (Store raw data)
Harmonization Process → Database (Reconcile costs + performance, calculate efficiency, generate context)
AI APIs → Database (Query harmonized data, generate recommendations)
Five Core APIs: From Data to Decisions
The harmonized data feeds five essential APIs designed specifically for AI-powered cost optimization:
Five specialized APIs turn harmonized data into actionable cost optimization strategies
1. Waste Detection API 💰
Purpose: Identify underutilized resources with immediate termination potential
GET /api/v1/ai/resources/waste-analysis
→ Returns: 15 idle instances costing $2,400/month with <5% utilization2. Rightsizing Recommendations API 📊
Purpose: Optimize instance sizes based on actual usage patterns
GET /api/v1/ai/resources/rightsizing-candidates
→ Returns: Move instance from m5.2xlarge to m5.xlarge, save $1,200 annually3. Commitment Savings API 🏦
Purpose: Identify Reserved Instance and Savings Plans opportunities
GET /api/v1/ai/costs/commitment-opportunities
→ Returns: Purchase 10x m5.large RIs for $85K investment, save $25K annually4. Portfolio Analysis API 📈
Purpose: High-level optimization overview across entire AWS footprint
GET /api/v1/ai/summary/portfolio-analysis
→ Returns: Total optimization potential: $180K annually (32% reduction)5. Usage Pattern Analysis API ⏰
Purpose: Identify automation opportunities for scheduled workloads
GET /api/v1/ai/patterns/workload-schedules
→ Returns: Dev environments idle 16 hours daily, auto-schedule saves $15K annuallyReal-World Performance: The Numbers
After three weeks of development and testing with complex AWS environments:
Data Processing Capabilities:
• CUR files: 1GB+ compressed files processed in under 10 minutes
• CloudWatch metrics: 10,000+ resources monitored with hourly updates
• Harmonization: Full account processing in under 30 minutes
• API response time: Sub-200ms for complex optimization queries
Optimization Detection Accuracy:
• Waste detection: 95%+ accuracy on obvious candidates (idle resources)
• Right-sizing: 85%+ accuracy with safety margins built in
• Commitment opportunities: 90%+ accuracy based on 90-day stability analysis
Technical Architecture: Built for Scale
Our system is designed to handle enterprise-scale AWS environments with high performance and reliability:
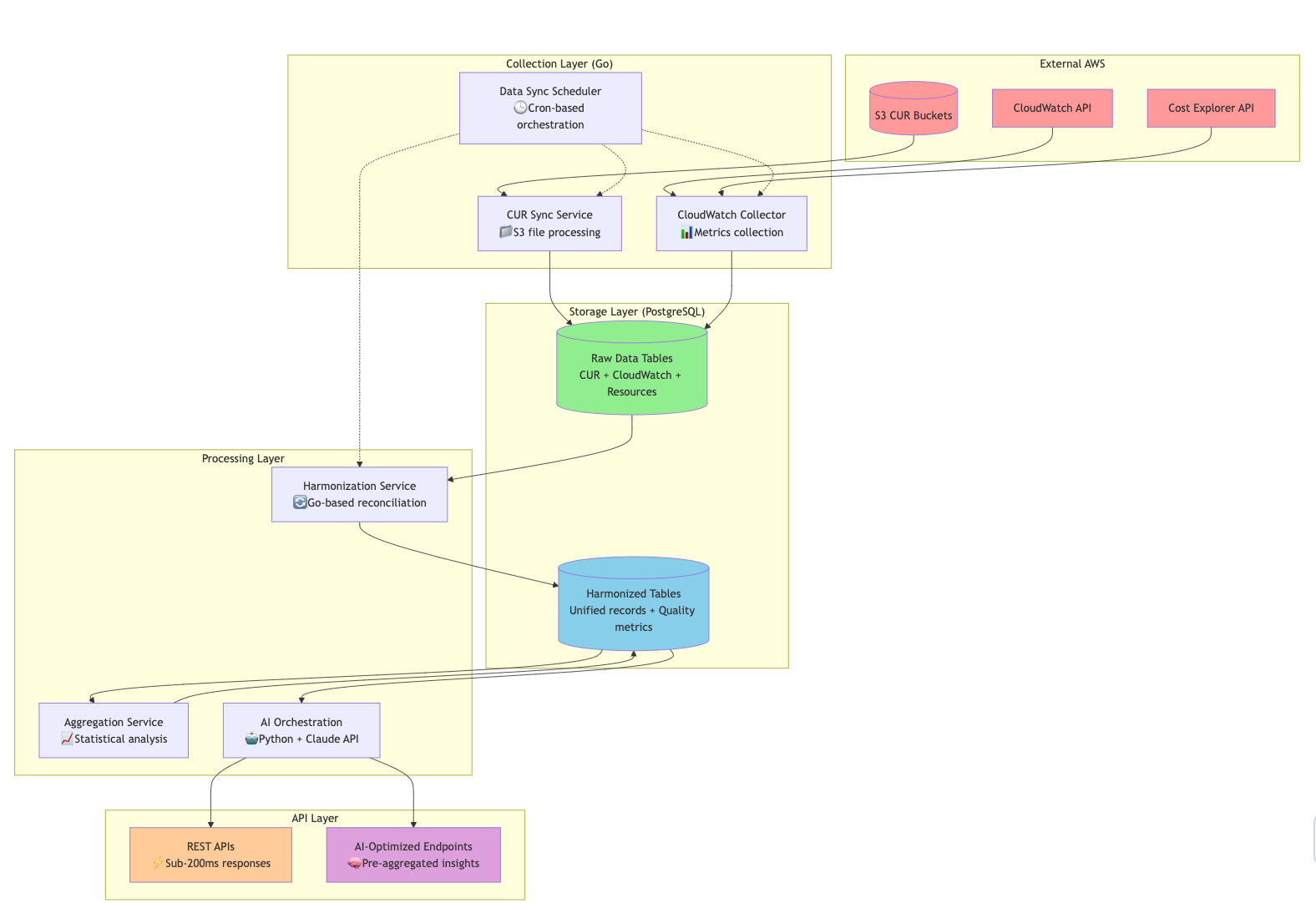
Complete technical stack: Go for performance, PostgreSQL for data, Python + Claude for AI
Key Technical Decisions:
🔧 Backend: Go services for high-performance data processing + Python for AI orchestration
🗄️ Database: PostgreSQL with optimized indexing for time-series and JSONB queries
⏰ Scheduling: Cron-based with intelligent gap detection and job overlap prevention
⚙️ Processing: Batch operations with progress tracking and automatic retry logic
📊 Storage: Harmonized data model optimized for both operational queries and AI consumption
Key Engineering Insights
1. Smart Sync Beats Brute Force
Rather than reprocessing everything daily, our smart sync logic:
Checks existing data completeness
Only processes genuinely new or updated information
Reduces processing time by 80% for incremental updates
2. Data Quality is Everything
We learned that perfect data is the enemy of good insights. Our system:
Calculates confidence scores for all recommendations
Provides data quality assessments
Works with incomplete data while flagging reliability
3. AI Context is King
The difference between generic recommendations and actionable insights is context. Our harmonized records include:
Historical usage patterns
Cost trend analysis
Risk assessment factors
Implementation complexity scoring
What’s Next: From Insights to Automated Actions
The current system generates highly accurate optimization recommendations. Our next phase focuses on making those recommendations easy to implement:
🔄 One-Click Fixes: Automated scripts for obvious optimizations (idle resource cleanup)
📋 Guided Implementation: Step-by-step workflows for complex changes (right-sizing with testing)
📊 ROI Tracking: Closed-loop measurement of actual savings vs. predicted savings
The Bottom Line
Building a robust FinOps data foundation is complex, but the payoff is substantial. Our system currently identifies an average of 20–30% cost optimization potential across the AWS environments we’ve tested.
More importantly, by harmonizing data from multiple sources and optimizing it for AI consumption, we’ve created a foundation that can evolve with both AWS service changes and AI model improvements.
For engineering teams spending $50K+ monthly on AWS: the time investment to build proper data foundations pays for itself within the first month of optimizations identified.
The era of spreadsheet-based cost optimization is ending. AI-native FinOps starts with AI-ready data, and that’s exactly what we’ve built.
Want to see this system in action? We’re building in public and sharing our learnings. Follow our journey on Twitter/X and LinkedIn as we continue optimizing the cost optimization process itself.
Tags: #FinOps #AI #Claude #VibeCoding #Golang #AWS #SystemDesign #Architecture